Fatherland

|
|
|
|
|
Acá está el thread.
Es laaaargo, pero bueno, resultado final, como soy un nerd, soy un programador, y los programadores programan hice el programa.
Lo que me sorprendió fué que apenas lo empecé a hacer, este programa completamente descartable, que no sirve para nada... estuve re prolijo.
Usé doctrings.
Usé doctests.
Lo hice con cuidado con el unicode.
Los comentarios son adecuados
La factorización en funciones está bien hecha
Hace apenas un año no hubiera hecho todo eso. Me parece que estoy terminando una etapa en mi (lenta, a los tropezones) evolución como programador, y estoy programando mejor que lo que venía haciendo.
Me pasaba mucho que como python te deja hacer las cosas rápido, las hacía rápido y mal, o lento y bien. Ahora las hago rápido y (creo) bien, o por lo menos mejor, o al menos menos peor.
De paso: éste es un excelente ejercicio para programadores "junior"!
Involucra manejo de strings que puede (o no) resolverse con regexps
Usar tests hace las cosas más fáciles en vez de más difíciles
Te hace "pensar en unicode"
El algoritmo en sí no es difícil, pero es algo tramposo
De paso, acá está el (tal vez pavotamente sobreestudiado) programa en cuestión, gaso.py:
# -*- coding: utf-8 -*-
"""
Éste es el módulo gasó.
Éste módulo provee la función gasear. Por ejemplo:
>>> gasear(u'rosarino')
u'rosarigasino'
"""
import unicodedata
import re
def gas(letra):
'''dada una letra X devuelve XgasX
excepto si X es una vocal acentuada, en cuyo caso devuelve
la primera X sin acento
>>> gas(u'a')
u'agasa'
>>> gas (u'\xf3')
u'ogas\\xf3'
'''
return u'%sgas%s'%(unicodedata.normalize('NFKD', letra).encode('ASCII', 'ignore'), letra)
def umuda(palabra):
'''
Si una palabra no tiene "!":
Reemplaza las u mudas de la palabra por !
Si la palabra tiene "!":
Reemplaza las "!" por u
>>> umuda (u'queso')
u'q!eso'
>>> umuda (u'q!eso')
u'queso'
>>> umuda (u'cuis')
u'cuis'
'''
if '!' in palabra:
return palabra.replace('!', 'u')
if re.search('([qg])u([ei])', palabra):
return re.sub('([qg])u([ei])', u'\\1!\\2', palabra)
return palabra
def es_diptongo(par):
'''Dado un par de letras te dice si es un diptongo o no
>>> es_diptongo(u'ui')
True
>>> es_diptongo(u'pa')
False
>>> es_diptongo(u'ae')
False
>>> es_diptongo(u'ai')
True
>>> es_diptongo(u'a')
False
>>> es_diptongo(u'cuis')
False
'''
if len(par) != 2:
return False
if (par[0] in 'aeiou' and par[1] in 'iu') or \
(par[1] in 'aeiou' and par[0] in 'iu'):
return True
return False
def elegir_tonica(par):
'''Dado un par de vocales que forman diptongo, decidir cual de las
dos es la tónica.
>>> elegir_tonica(u'ai')
0
>>> elegir_tonica(u'ui')
1
'''
if par[0] in 'aeo':
return 0
return 1
def gasear(palabra):
"""
Convierte una palabra de castellano a rosarigasino.
>>> gasear(u'rosarino')
u'rosarigasino'
>>> gasear(u'pas\xe1')
u'pasagas\\xe1'
Los diptongos son un problema a veces:
>>> gasear(u'cuis')
u'cuigasis'
>>> gasear(u'caigo')
u'cagasaigo'
Los adverbios son especiales para el castellano pero no
para el rosarino!
>>> gasear(u'especialmente')
u'especialmegasente'
"""
#from pudb import set_trace; set_trace()
# Primero el caso obvio: acentos.
# Lo resolvemos con una regexp
if re.search(u'[\xe1\xe9\xed\xf3\xfa]',palabra):
return re.sub(u'([\xe1\xe9\xed\xf3\xfa])',lambda x: gas(x.group(0)),palabra,1)
# Siguiente problema: u muda
# Reemplazamos gui gue qui que por g!i g!e q!i q!e
# y lo deshacemos antes de salir
palabra=umuda(palabra)
# Que hacemos? Vemos en qué termina
if palabra[-1] in 'nsaeiou':
# Palabra grave, acento en la penúltima vocal
# Posición de la penúltima vocal:
pos=list(re.finditer('[aeiou]',palabra))[-2].start()
else:
# Palabra aguda, acento en la última vocal
# Posición de la última vocal:
pos=list(re.finditer('[aeiou]',palabra))[-1].start()
# Pero que pasa si esa vocal es parte de un diptongo?
if es_diptongo(palabra[pos-1:pos+1]):
pos += elegir_tonica(palabra[pos-1:pos+1])-1
elif es_diptongo(palabra[pos:pos+2]):
pos += elegir_tonica(palabra[pos:pos+2])
return umuda(palabra[:pos]+gas(palabra[pos])+palabra[pos+1:])
if __name__ == "__main__":
import doctest
doctest.testmod()I've just uploaded the 0.13 version of rst2pdf, a tool to convert reStructured text to PDF using Reportlab to http://rst2pdf.googlecode.com
rst2pdf supports the full reSt syntax, works as a sphinx extension, and has many extras like limited support for TeX-less math, SVG images, embedding fragments from PDF documents, True Type font embedding, and much more.
This is a major version, and has lots of improvements over 0.12.3, including but not limited to:
New TOC code (supports dots between title and page number)
New extension framework
New preprocessor extension
New vectorpdf extension
Support for nested stylesheets
New headerSeparator/footerSeparator stylesheet options
Foreground image support (useful for watermarks)
Support transparency (alpha channel) when specifying colors
Inkscape extension for much better SVG support
Ability to show total page count in header/footer
New RSON format for stylesheets (JSON superset)
Fixed Issue 267: Support :align: in figures
Fixed Issue 174 regression (Indented lines in line blocks)
Fixed Issue 276: Load stylesheets from strings
Fixed Issue 275: Extra space before lineblocks
Fixed Issue 262: Full support for Reportlab 2.4
Fixed Issue 264: Splitting error in some documents
Fixed Issue 261: Assert error with wordaxe
Fixed Issue 251: added support for rst2pdf extensions when using sphinx
Fixed Issue 256: ugly crash when using SVG images without SVG support
Fixed Issue 257: support aafigure when using sphinx/pdfbuilder
Initial support for graphviz extension in pdfbuilder
Fixed Issue 249: Images distorted when specifiying width and height
Fixed Issue 252: math directive conflicted with sphinx
Fixed Issue 224: Tables can be left/center/right aligned in the page.
Fixed Issue 243: Wrong spacing for second paragraphs in bullet lists.
Big refactoring of the code.
Support for Python 2.4
Fully reworked test suite, continuous integration site.
Optionally use SWFtools for PDF images
Fixed Issue 231 (Smarter TTF autoembed)
Fixed Issue 232 (HTML tags in title metadata)
Fixed Issue 247 (printing stylesheet)
¿Ya te asustaste? No lo hagas, el problema es el proceso de contratación.
Sí, hay montones de personas que se presentan para trabajos de programador y no saben programar. Eso es normal.
Está relacionado con una cosa que escribió Joel Spolsky (extrañamente, socio de Atwood en stackoverflow.com).
Suponéte que querés contratar a alguien en el top 1% de los programadores.
Tenés 100 postulantes, de ellos 99 no pueden programar. 1 puede, y lo contratás.
Después la empresa de al lado necesita lo mismo. Tienen 100 postulantes, 99 no pueden programar... ¡y 80 son los mismos que la otra compañía rechazó!
Así que no, contratar al mejor de 100 no es la manera de tener un programador "top 1%", es simplemente tu intuición estadística que te hace equivocar.
No querés contratar a alguien en el top 1% de los postulantes, querés uno en el top 1% de programadores. Diferentes universos.
Estas dos cosas son los dos lados de la misma moneda. 99% de los postulantes son inútiles, por eso son postulantes, porque no pueden conseguir trabajo y no tienen trabajo porque son inútiles como programadores.
Juzgar a los programadores por el standard de los postulantes que se presentan es como juzgar la calidad de un restaurante lamiendo su tacho de basura.
Ahora, habiendo entendido esto, ¿cómo se encuentra un programador que pueda programar?
¡Fácil! ¡Buscás uno que tenga programas para mostrarte!
Nunca contrataría a un programador que no me pueda mostrar código. Tiene que tener un problema porque los programadores programan.
Es lo que hacemos. ¿Si no lo hacemos que somos? ¿Teóricos?
Veamos algunas objeciones obvias:
Programó para su trabajo anterior y no lo puede mostrar.
Ok, lohizo. ¿Qué más escribió? ¿Algo open source? ¿fragmentos en un blog? ¿Respuestas en stackoverflow?
¿Nada? ¿No escribió nada sin cobrar? No es el que quiero. Si sólo programa por dinero no tiene pasión por la programación, o no lo disfruta. Probablemente no es muy bueno tampoco.
Está terminando la universidad, todavía no escribió mucho.
¿Porqué? ¿Qué está esperando? ¿Qué lo detiene? Lleva años estudiando como programar! ¿Qué hizo con el conocimiento que fué adquiriendo? ¿Lo guarda para cuando cumpla 25? ¿No practicó su arte? No es el programador que buscamos.
Pero conseguir alguien que te muestre código no es suficiente por supuesto. También tiene que ser buen código, si estás seriamente tratando de contratar programadores excelentes.
Así que aquí hay unos criterios extra:
Fijáte en qué lenguakes programa. Si programa COBOL por gusto puede o no ser lo que necesitás.
Open source == bonus points: quiere decir que no lo avergüenza su código, y hace que sus credenciales sean triviales de verificar.
Si es el líder de un proyecto con múltiples colaboradores y lo hace bien, está a mitad de camino de ser un programador/manager, muchos bonus points!
Proyectos con un historial de commits largo muestran responsabilidad y criterio.
Listas de correo de desarrollo te permiten estimar su personalidad. ¿Es irritante? ¿Es sensible? ¿Es molesto?
Y después está lo obvio, referencias, entrevistas, ejercicios, pero esos son filtros secundarios, lo importante es que pueda programar, y mostrarte su código es la forma de hacerlo.
Obviamente no está ni cerca de ser útil para algo, pero... puede hacer listas itemizadas o numeradas anidadas.
Acá hay una captura del editor y de la salida PDF que produce vía reStructured Text:
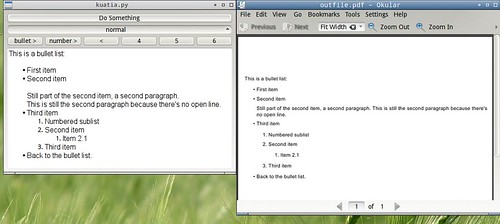
No me parece que esté tan mal.