Fatherland

|
|
|
|
|
Yesterday in the PyAr mailing list a "silly" subject appeared: how would you translate spanish to rosarino?
For those reading in english: think of rosarino as a sort of pig latin, where the tonic vowel X is replaced with XgasX, thus "rosario" -> "rosagasario".
In english this would be impossible, but spanish is a pretty regular language, and a written word has enough information to know how to pronounce it, including the location of the tonic vowel, so this is possible to do.
Here is the thread.
It's looong but, final outcome, since I am a nerd, and a programmerm and programmers program, I wrote it.
What surprised me is that as soon as I started doing it, this throwaway program, completely useless...I did it cleanly.
I used doctrings.
I used doctests.
I was careful with unicode.
Comments are adequate
Factoring into functions is correct
A year ago I wouldn't have done that. I think I am finishing a stage in my (slow, stumbling) evolution as a programmer, and am coding better than before.
I had a tendency to, since python lets you write fast, write fast and dirty. Or slow and clean. Now I can code fast and clean, or at least cleaner.
BTW: this would be an excellent exercise for "junior" programmers!
It involves string manipulation which may (or may not) be handled with regexps.
Using tests is very quickly rewarding
Makes you "think unicode"
The algorithm itself is not complicated, but tricky.
BTW: here is the (maybe stupidly overthought) program, gaso.py:
# -*- coding: utf-8 -*-
"""
Éste es el módulo gasó.
Éste módulo provee la función gasear. Por ejemplo:
>>> gasear(u'rosarino')
u'rosarigasino'
"""
import unicodedata
import re
def gas(letra):
'''dada una letra X devuelve XgasX
excepto si X es una vocal acentuada, en cuyo caso devuelve
la primera X sin acento
>>> gas(u'a')
u'agasa'
>>> gas (u'\xf3')
u'ogas\\xf3'
'''
return u'%sgas%s'%(unicodedata.normalize('NFKD', letra).encode('ASCII', 'ignore'), letra)
def umuda(palabra):
'''
Si una palabra no tiene "!":
Reemplaza las u mudas de la palabra por !
Si la palabra tiene "!":
Reemplaza las "!" por u
>>> umuda (u'queso')
u'q!eso'
>>> umuda (u'q!eso')
u'queso'
>>> umuda (u'cuis')
u'cuis'
'''
if '!' in palabra:
return palabra.replace('!', 'u')
if re.search('([qg])u([ei])', palabra):
return re.sub('([qg])u([ei])', u'\\1!\\2', palabra)
return palabra
def es_diptongo(par):
'''Dado un par de letras te dice si es un diptongo o no
>>> es_diptongo(u'ui')
True
>>> es_diptongo(u'pa')
False
>>> es_diptongo(u'ae')
False
>>> es_diptongo(u'ai')
True
>>> es_diptongo(u'a')
False
>>> es_diptongo(u'cuis')
False
'''
if len(par) != 2:
return False
if (par[0] in 'aeiou' and par[1] in 'iu') or \
(par[1] in 'aeiou' and par[0] in 'iu'):
return True
return False
def elegir_tonica(par):
'''Dado un par de vocales que forman diptongo, decidir cual de las
dos es la tónica.
>>> elegir_tonica(u'ai')
0
>>> elegir_tonica(u'ui')
1
'''
if par[0] in 'aeo':
return 0
return 1
def gasear(palabra):
"""
Convierte una palabra de castellano a rosarigasino.
>>> gasear(u'rosarino')
u'rosarigasino'
>>> gasear(u'pas\xe1')
u'pasagas\\xe1'
Los diptongos son un problema a veces:
>>> gasear(u'cuis')
u'cuigasis'
>>> gasear(u'caigo')
u'cagasaigo'
Los adverbios son especiales para el castellano pero no
para el rosarino!
>>> gasear(u'especialmente')
u'especialmegasente'
"""
#from pudb import set_trace; set_trace()
# Primero el caso obvio: acentos.
# Lo resolvemos con una regexp
if re.search(u'[\xe1\xe9\xed\xf3\xfa]',palabra):
return re.sub(u'([\xe1\xe9\xed\xf3\xfa])',lambda x: gas(x.group(0)),palabra,1)
# Siguiente problema: u muda
# Reemplazamos gui gue qui que por g!i g!e q!i q!e
# y lo deshacemos antes de salir
palabra=umuda(palabra)
# Que hacemos? Vemos en qué termina
if palabra[-1] in 'nsaeiou':
# Palabra grave, acento en la penúltima vocal
# Posición de la penúltima vocal:
pos=list(re.finditer('[aeiou]',palabra))[-2].start()
else:
# Palabra aguda, acento en la última vocal
# Posición de la última vocal:
pos=list(re.finditer('[aeiou]',palabra))[-1].start()
# Pero que pasa si esa vocal es parte de un diptongo?
if es_diptongo(palabra[pos-1:pos+1]):
pos += elegir_tonica(palabra[pos-1:pos+1])-1
elif es_diptongo(palabra[pos:pos+2]):
pos += elegir_tonica(palabra[pos:pos+2])
return umuda(palabra[:pos]+gas(palabra[pos])+palabra[pos+1:])
if __name__ == "__main__":
import doctest
doctest.testmod()I've just uploaded the 0.13 version of rst2pdf, a tool to convert reStructured text to PDF using Reportlab to http://rst2pdf.googlecode.com
rst2pdf supports the full reSt syntax, works as a sphinx extension, and has many extras like limited support for TeX-less math, SVG images, embedding fragments from PDF documents, True Type font embedding, and much more.
This is a major version, and has lots of improvements over 0.12.3, including but not limited to:
New TOC code (supports dots between title and page number)
New extension framework
New preprocessor extension
New vectorpdf extension
Support for nested stylesheets
New headerSeparator/footerSeparator stylesheet options
Foreground image support (useful for watermarks)
Support transparency (alpha channel) when specifying colors
Inkscape extension for much better SVG support
Ability to show total page count in header/footer
New RSON format for stylesheets (JSON superset)
Fixed Issue 267: Support :align: in figures
Fixed Issue 174 regression (Indented lines in line blocks)
Fixed Issue 276: Load stylesheets from strings
Fixed Issue 275: Extra space before lineblocks
Fixed Issue 262: Full support for Reportlab 2.4
Fixed Issue 264: Splitting error in some documents
Fixed Issue 261: Assert error with wordaxe
Fixed Issue 251: added support for rst2pdf extensions when using sphinx
Fixed Issue 256: ugly crash when using SVG images without SVG support
Fixed Issue 257: support aafigure when using sphinx/pdfbuilder
Initial support for graphviz extension in pdfbuilder
Fixed Issue 249: Images distorted when specifiying width and height
Fixed Issue 252: math directive conflicted with sphinx
Fixed Issue 224: Tables can be left/center/right aligned in the page.
Fixed Issue 243: Wrong spacing for second paragraphs in bullet lists.
Big refactoring of the code.
Support for Python 2.4
Fully reworked test suite, continuous integration site.
Optionally use SWFtools for PDF images
Fixed Issue 231 (Smarter TTF autoembed)
Fixed Issue 232 (HTML tags in title metadata)
Fixed Issue 247 (printing stylesheet)
If you haven't read Jeff Atwood's Why Can't Programmers.. Program? go ahead, then come back.
Now, are you scared enough? Don't be, the problem there is with the hiring process.
Yes, there are lots of people who show up for programming positions and can't program. That's not unusual!
It's related to something I read by Joel Spolsky (amazingly, Jeff Atwood's partner in stackoverflow.com).
Suppose you are a company that tries to hire in the top 1% of programmers, and have an open position.
You get 100 applicants. Of those, 99 can't program. 1 can. You hire him.
Then the company next door needs to do the same thing. They may get 100 applicant. 99 can't program ... and probably 80 of them are the same the previous company rejected before!
So no, hiring the best 1 out of 100 is not a way to get a programmer in the top 1% at all, that's just statistics intuition getting the worse of you.
You don't want to hire in the top 1% of applicants, you want to hire in the top 1% of programmers. Different universes.
These two things are the two sides of the same coin. 99% of applicants are useless, that's why they are applicants, because they can't get a job and they can't get a job because they are useless as programmers.
So, judging programmers by the standard of the applicants you get is like judging quality of a restaurant by licking its dumpster.
But now, having taken care of this, how do you find a programmer that can actually program?
Easy! Find one that has programs he can show you!
I would never hire a programmer that can't show me code. There must be something wrong with him, because programmers write programs.
That's just what we do. If we didn't what kind of programmers would we be?
Let's see some obvious objections to my argument:
He wrote code for his previous employer and can't show it.
So, he did. What else has he written? Some open source code? Maybe snippets in a blog? Answers in stackoverflow?
Nothing? He has written nothing he was not paid to write? He is not who I want. He only programs for money, he lacks passion for programming, he doesn't enjoy it. He is probably not very good at it.
He is just finishing college, he has not written much code yet!
Why? What stopped him? He has been learning to program for years, what has he done with the knowledge he has been receiving? Saving it for his 25th brthday party? He has not practiced his craft? Not the programmer I need.
But having him show you code is not enough, of course. It also has to be good code, if you are serious about hiring excellent programmers.
So here's some bonus criteria:
Check the languages he uses. If he codes COBOL for pleasure, he may or may not be what you want.
Open source == bonus points: it means he is not ashamed of his code, plus it makes his credentials trivial to verify.
If he leads a project with multiple contributors and does a good job he is half way to becoming a programmer/manager, so huge bonus points.
Projects with long commit histories show responsability and a level head.
Development mailing lists let you gauge his personality. Is he abrasive? Is he thin-skinned? Is he annoying?
Then there's the obvious stuff, references from previous employers, interviews, exercises, an such. But those are the least important filters, the most important thing is that he must be able to code. And showing you his code is the way to do it.
As mentioned previously, I am hacking a bit on a proof-of-concept word processor. Right now, it's hosted on googlecode and called kuatia.
Now, it is far from being useful for anything, but... it can do nested itemized and bulleted lists.
Here's a screenie of the editor and the PDF output it produces via reStructured Text:
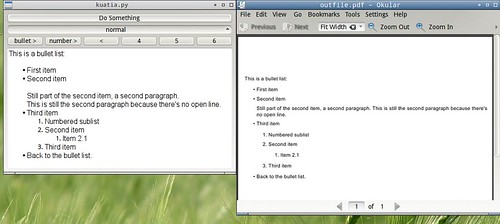
Personally I think that's not too bad.